خوشهبندی در یادگیری ماشین چیست؟
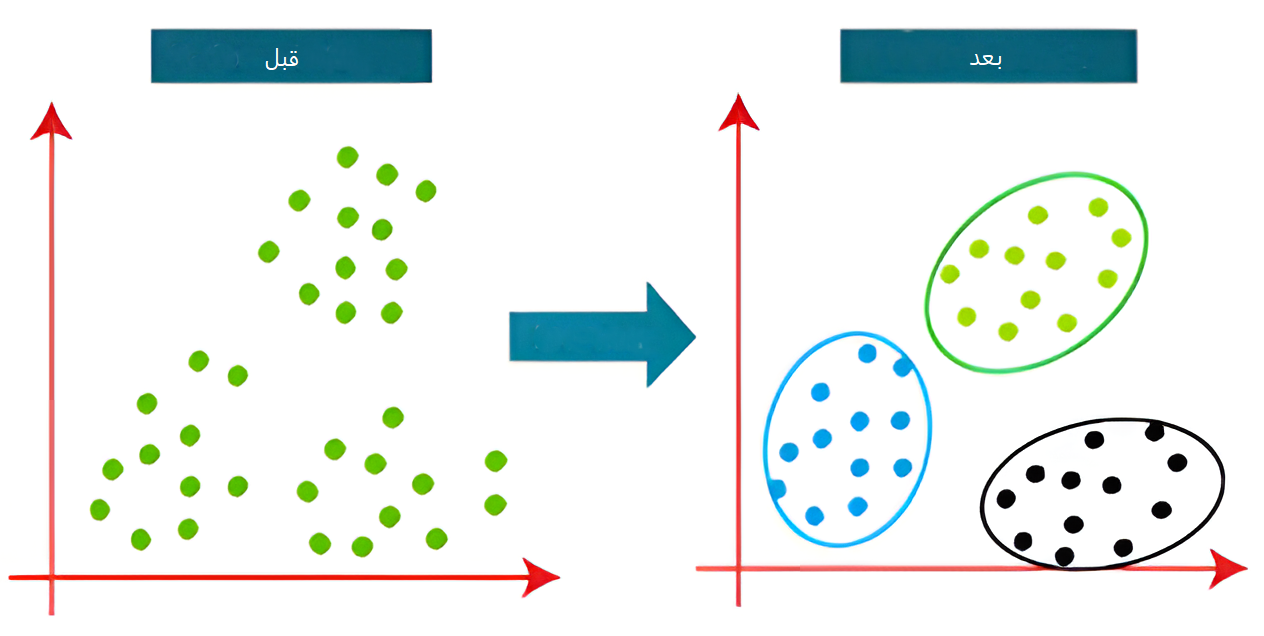
خوشهبندی در یادگیری ماشین چیست؟ وقتی دادهها خودشان حرف میزنند
تصور کنید وارد یک کتابخانه بزرگ شدهاید که هیچ طبقهبندی ندارد و هزاران کتاب روی زمین ریخته شده است. اگر بخواهید این کتابها را مرتب کنید، چهکار میکنید؟ احتمالاً کتابهای علمی را کنار هم، رمانها را در گروهی دیگر و کتابهای تاریخی را در دستهای جداگانه قرار میدهید.
در دنیای یادگیری ماشین، به این عملِ «گروهبندیِ دادههای مشابه»، خوشهبندی (Clustering) میگویند. برخلاف بسیاری از الگوریتمها که نیاز دارند به آنها بگوییم هر داده چیست (یادگیری نظارتشده)، خوشهبندی در دسته یادگیری بدون ناظر (Unsupervised Learning) قرار دارد. یعنی الگوریتم هیچ راهنمایی ندارد و خودش باید شباهتها را کشف کند.
هدف اصلی خوشهبندی
هدف خوشهبندی این است که:
- دادههای داخل یک گروه (خوشه) بیشترین شباهت را به هم داشته باشند.
- دادههای گروههای مختلف، بیشترین تفاوت را با هم داشته باشند.
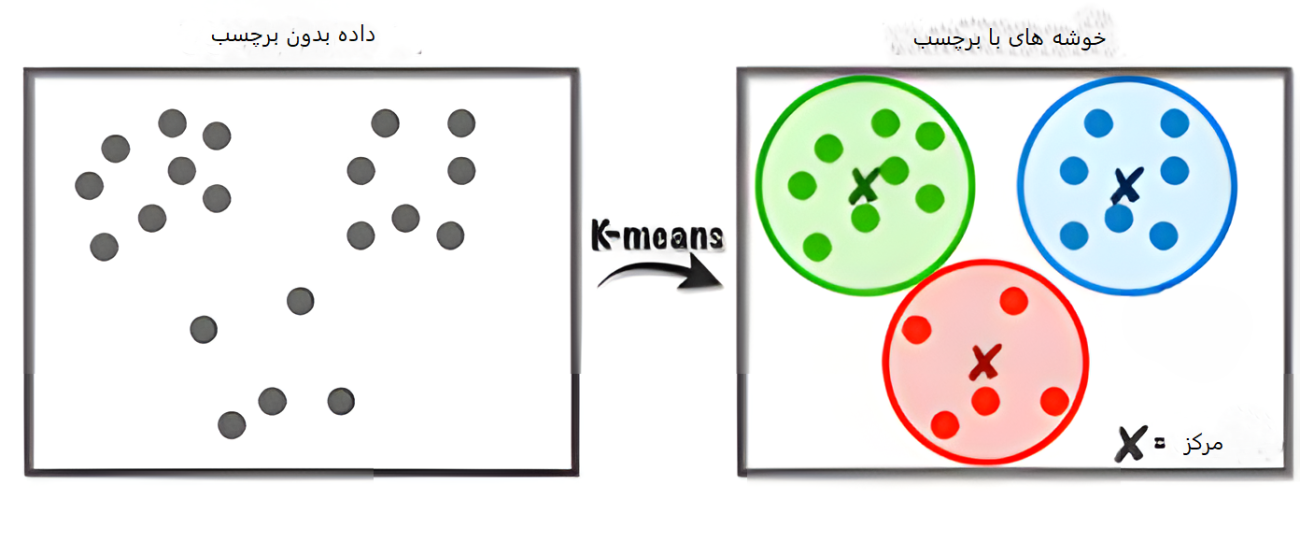
مشهورترین الگوریتم: K-Means (کی-میانگین)
الگوریتم K-Means سادهترین و محبوبترین ابزار برای خوشهبندی است. فرآیند آن به زبان ساده اینگونه است:
- تعیین تعداد (K): ابتدا مشخص میکنیم که میخواهیم دادهها به چند دسته تقسیم شوند (مثلاً ۳ دسته).
- انتخاب مراکز فرضی: الگوریتم ۳ نقطه را به صورت تصادفی به عنوان مرکزِ هر خوشه انتخاب میکند.
- انتساب: هر داده به نزدیکترین مرکز نسبت داده میشود.
- بهروزرسانی: میانگین دادههای هر خوشه محاسبه شده و مرکز خوشه به آن نقطه جدید منتقل میشود.
- تکرار: این کار آنقدر تکرار میشود تا مراکز دیگر جابجا نشوند و خوشهها ثابت بمانند.
کاربردهای دنیای واقعی
- بخشبندی مشتریان (Segmentation): فروشگاههای آنلاین مشتریان را بر اساس سلیقه خرید دستهبندی میکنند تا تبلیغات هدفمند برایشان بفرستند.
- تشخیص ناهنجاری: دستهبندی تراکنشهای بانکی برای شناسایی خریدهای غیرعادی (کلاهبرداری).
- تحلیل شبکههای اجتماعی: پیدا کردن گروههای دوستانه یا افرادی که علایق مشترک دارند.
- فشردهسازی تصویر: کاهش تعداد رنگهای تصویر با خوشهبندی پیکسلهای مشابه.
تفاوت خوشهبندی با طبقهبندی (Classification)
خیلیها این دو را اشتباه میگیرند، اما تفاوت ساده است:
- طبقهبندی: ما قبلاً برچسبها را میشناسیم (مثلاً: این ایمیل “اسپم” است یا “عادی”).
- خوشهبندی: هیچ برچسبی وجود ندارد؛ الگوریتم خودش بر اساس شباهت، دستهها را میسازد (مثلاً: اینها را در گروه A و آن یکیها را در گروه B بگذار، چون به هم شبیهترند).
مزایا و چالشها
مزایا:
- کشف الگوهای پنهانی که انسان نمیبیند.
- کاربردی برای حجم انبوه دادههای بدون برچسب.
چالشها:
- انتخاب تعداد خوشهها (K): اگر اشتباه انتخاب کنید، نتایج بیمعنی میشوند.
- حساسیت به دادههای پرت (Outliers): دادههای بسیار دورافتاده میتوانند میانگین خوشهها را خراب کنند.
جمعبندی
خوشهبندی مثل یک ذرهبین هوشمند است که به ما کمک میکند در دریایی از اطلاعات، نظم پیدا کنیم. با استفاده از این الگوریتم، کسبوکارها میتوانند مشتریان خود را بهتر بشناسند و سیستمهای امنیتی میتوانند رفتارهای عجیب را سریعتر شناسایی کنند.