یادگیری فدرال چیست؟
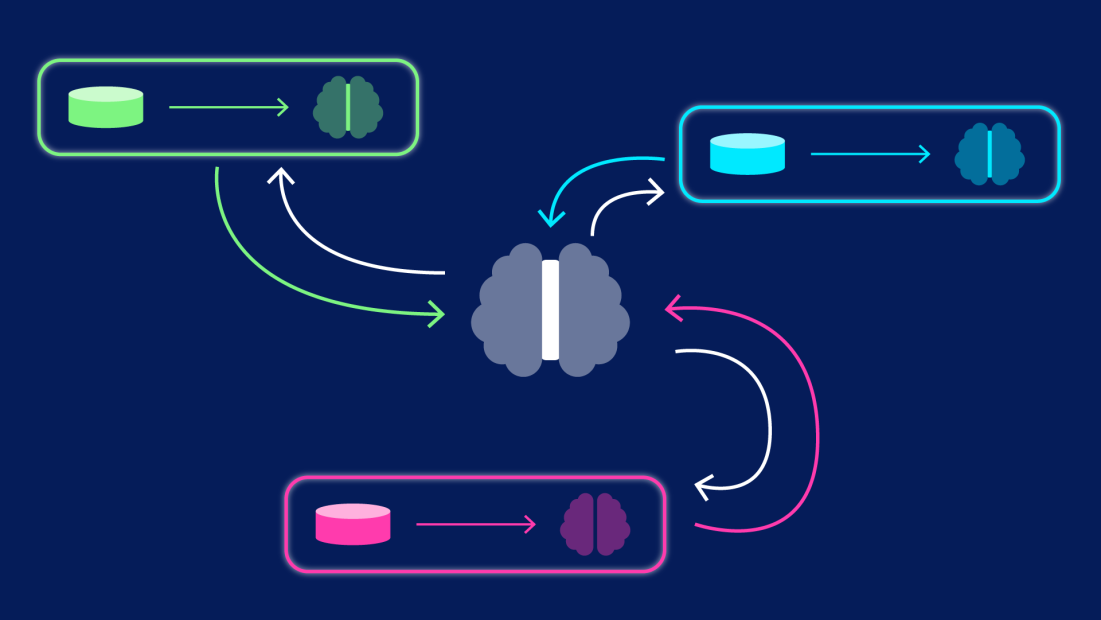
یادگیری فدرال چیست؟ (تعریف ساده)
در بسیاری از پروژههای هوش مصنوعی، برای آموزش مدل باید دادهها را در یک مکان مرکزی جمع کرد. اما این کار معمولاً با دو مانع بزرگ روبهروست:
- حریم خصوصی و مقررات: انتقال دادههای شخصی (سلامت، موقعیت مکانی، رفتار کاربران) میتواند ریسک حقوقی و امنیتی ایجاد کند.
- هزینه و زیرساخت: گردآوری، پاکسازی، انتقال و ذخیره حجم عظیم دادهها زمانبر و گران است.
یادگیری فدرال (Federated Learning) پاسخی است به این وضعیت: مدل آموزش میبیند، اما دادهها جابهجا نمیشوند. فقط «دانش» به شکل بهروزرسانیهای مدل میان دستگاهها یا مراکز توزیع میشود.
در یادگیری فدرال:
- چندین دستگاه/سازمان (Client) دادههای خود را نگه میدارند.
- سرور مرکزی (Server) مدل اولیه را پخش میکند.
- هر کلاینت با دادههای محلی خود مدل را آموزش میدهد.
- کلاینتها فقط پارامترهای مدل یا گرادیانها را (نه داده خام) به سرور میفرستند.
- سرور آن بهروزرسانیها را تجمیع میکند و مدل جهانی را آپدیت میکند.
- این چرخه تا رسیدن به کیفیت قابل قبول تکرار میشود.
ایده اصلی: «همکاری بدون انتقال داده»
فکر کنید بیمارستانها میخواهند یک مدل تشخیصی را آموزش دهند، اما نمیتوانند دادههای بیماران را بین خودشان به اشتراک بگذارند. در یادگیری فدرال:
- هر بیمارستان مدل را روی دادههای خودش آموزش میدهد.
- سرور فقط نسخه تجمیعشده مدل را برمیگرداند.
- در نتیجه، دانش از کل سیستم یاد گرفته میشود بدون اینکه دادهها از محل خارج شوند.
معماری یادگیری فدرال
به طور معمول سه جزء داریم:
-
سرور هماهنگکننده (Coordinator):
- ارسال مدل اولیه
- جمعآوری بهروزرسانیها
- تجمیع و تولید مدل جهانی
-
کلاینتها (Clients):
- کاربر موبایل، سرور سازمانی، یا دستگاههای لبه (Edge)
- آموزش محلی با دادههای خود
- ارسال آپدیت مدل به سرور
-
کانال ارتباطی (Communication Layer):
- شبکه برای ارسال گرادیان/وزنها
- معمولاً باید امن باشد (رمزنگاری، احراز هویت، کنترل دسترسی)
الگوریتمهای رایج در یادگیری فدرال
۱) Federated Averaging (FedAvg)
رایجترین روش، تجمیع میانگین وزندار است:
- هر کلاینت kk مدل را با دادههای خود بهروزرسانی میکند و یک مجموعه وزن/گرادیان ارسال میدهد.
- سرور میانگین وزندار آنها را میسازد.
۲) روشهای بهبود FedAvg
به دلیل مشکلاتی مثل «ناسازگاری داده» (Non-IID) در عمل، الگوریتمهای دیگری هم مطرح شدهاند:
- FedProx
- SCAFFOLD
- FedAdam / FedYogi (در چارچوبهای بهینهسازی مشابه SGD/Adam)
اینها تلاش میکنند همگرایی را پایدارتر کنند.
چرا دادهها در دنیای واقعی Non-IID هستند؟
حتی اگر همه کلاینتها یک کار مشابه انجام دهند، دادههایشان معمولاً یکسان نیستند. مثالها:
- در بانک: هر منطقه یا گروه مشتری رفتار متفاوتی دارد.
- در سلامت: پروفایل بیماران در هر بیمارستان متفاوت است.
- در موبایل: کاربران هر کشور/نسل/عادت زبانی متفاوتی دارند.
این «ناهمگونی توزیع دادهها» میتواند آموزش فدرال را کند یا ناپایدار کند.
مزایای یادگیری فدرال
-
حفظ حریم خصوصی دادهها
- داده خام جابهجا نمیشود.
- کمک میکند اصل Privacy by Design رعایت شود.
-
کاهش ریسک و هزینه انتقال داده
- دیگر نیاز به انتقال حجم زیادی از داده به دیتاسنتر نیست.
-
سازگاری با اکوسیستمهای چندسازمانی
- دانشگاهها، بیمارستانها، شرکتها و اپراتورها میتوانند بدون هماشتراکی داده مشترک آموزش دهند.
-
قابلیت یادگیری در محیطهای توزیعشده
- مناسب دستگاههای لبه و محیطهایی با محدودیت اتصال دائمی.
محدودیتها و چالشهای مهم
حتی با اینکه دادهها منتقل نمیشوند، فدرال هم «جادویی» نیست:
-
نشت اطلاعات از طریق آپدیتها
- گرادیانها/وزنها میتوانند منبع اطلاعات باشند و در برخی حملات امکان استخراج الگوهای حساس وجود دارد.
- بنابراین معمولاً نیاز به تکنیکهای اضافی مثل رمزنگاری امن یا محافظتهای حریم خصوصی هست.
-
هزینه ارتباطی (Communication Bottleneck)
- ارسال مکرر آپدیتهای مدل میتواند پهنای باند را تحت فشار قرار دهد.
- راهکارها: کاهش دفعات ارتباط، فشردهسازی آپدیتها، کوانتایزیشن، یا انتخاب زیرمجموعه کلاینتها.
-
ناهمگونی دادهها (Non-IID)
- ممکن است مدل جهانی بهترین نمایندگی را نیاموزد یا به کندی همگرا شود.
-
ناپایداری کلاینتها
- در موبایل، کاربران همیشه آنلاین نیستند.
- در نتیجه ممکن است برخی دورها مشارکت نکنند (Partial Participation).
-
حمله زنجیرهای/کلاینت خرابکار
- اگر یکی از کلاینتها عمداً آپدیت غلط ارسال کند، ممکن است مدل جهانی آسیب ببیند.
- نیاز به تشخیص ناهنجاری و مقاومت در برابر Poisoning وجود دارد.
برای افزایش امنیت، چه رویکردهایی اضافه میشود؟
در پروژههای واقعی معمولاً ترکیبی از موارد زیر استفاده میشود:
- رمزنگاری و تجمیع امن (Secure Aggregation)
- حریم خصوصی تفاضلی (Differential Privacy)
- کنترل مشارکت و اعتبارسنجی کلاینتها
- Robust Aggregation (مثلاً رد آپدیتهای پرت/خرابکار)
سناریوهای واقعی کاربرد
-
سلامت
- آموزش مدلهای تشخیصی یا پیشآگهی بدون ارسال داده بیماران.
-
موبایل و کیبوردها
- شخصیسازی مدلها با دادههای محلی کاربر، بدون اینکه متن کاربر برای شرکت ارسال شود.
-
جایگزین کردن همکاری بین سازمانها
- وقتی چند سازمان نمیتوانند داده را به دلایل قانونی/حساسیت به اشتراک بگذارند.
-
صنایع و کارخانهها (Industrial IoT)
- آموزش مدل برای عیبیابی یا پیشبینی خرابی با دادههای هر خط تولید.
جمعبندی
یادگیری فدرال (Federated Learning) یک مدل همکاری هوشمندانه است:
به جای جابهجا کردن دادهها، «یادگیری» را منتقل میکند. این روش میتواند هم کیفیت مدل را بالا ببرد و هم با کاهش انتقال دادههای حساس، حریم خصوصی را تقویت کند—هرچند همچنان چالشهایی مثل نشت از طریق آپدیتها، ناهمگونی داده و محدودیت ارتباط وجود دارد.