شبکههای عصبی کانولوشنی (CNN) چگونه کار میکنند؟ راهنمای کامل
شبکههای عصبی کانولوشنی (CNN) چگونه کار میکنند؟
در سالهای اخیر، هوش مصنوعی پیشرفت چشمگیری داشته است. بسیاری از فناوریهایی که امروزه از آنها استفاده میکنیم، مانند تشخیص چهره، خودروهای خودران و سیستمهای تشخیص اشیا، بر پایه شبکههای عصبی کانولوشنی یا CNN ساخته شدهاند.
اما سؤال مهم این است که شبکههای عصبی کانولوشنی چگونه کار میکنند؟ چگونه یک کامپیوتر میتواند تصویر یک گربه را از یک سگ تشخیص دهد یا چهره افراد را شناسایی کند؟
برای پاسخ به این سؤال، باید ابتدا با مفهوم CNN و ساختار آن آشنا شویم.
شبکه عصبی کانولوشنی (CNN) چیست؟
شبکه عصبی کانولوشنی (Convolutional Neural Network) نوعی شبکه عصبی مصنوعی است که بهطور ویژه برای تحلیل تصاویر و دادههای بصری طراحی شده است.
برخلاف شبکههای عصبی سنتی، CNN میتواند ویژگیهای مهم تصویر را بهصورت خودکار استخراج کند. در نتیجه، دیگر نیازی نیست برنامهنویس ویژگیهای تصویر را بهصورت دستی تعریف کند.
به همین دلیل، CNN به یکی از مهمترین ابزارهای بینایی کامپیوتر تبدیل شده است.
چرا CNN برای تصاویر مناسب است؟
تصاویر از میلیونها پیکسل تشکیل شدهاند. اگر بخواهیم تمام این پیکسلها را مستقیماً به یک شبکه عصبی معمولی بدهیم، تعداد پارامترها بسیار زیاد خواهد شد.
در نتیجه:
- حافظه زیادی مصرف میشود.
- آموزش مدل بسیار کند میشود.
- احتمال بیشبرازش افزایش پیدا میکند.
برای حل این مشکل، CNN از ساختاری استفاده میکند که فقط روی بخشهای کوچک تصویر تمرکز دارد.
به عبارت دیگر، مدل ابتدا الگوهای ساده را یاد میگیرد و سپس به سراغ ویژگیهای پیچیدهتر میرود.
ایده اصلی CNN چیست؟
ایده اصلی CNN بسیار شبیه نحوه عملکرد سیستم بینایی انسان است.
زمانی که انسان به یک تصویر نگاه میکند، ابتدا لبهها، خطوط و اشکال ساده را تشخیص میدهد. سپس مغز این اطلاعات را ترکیب کرده و اشیای پیچیدهتر را شناسایی میکند.
شبکههای کانولوشنی نیز دقیقاً همین کار را انجام میدهند.
در ابتدا ویژگیهای ساده استخراج میشوند و سپس لایههای عمیقتر این ویژگیها را با هم ترکیب میکنند.
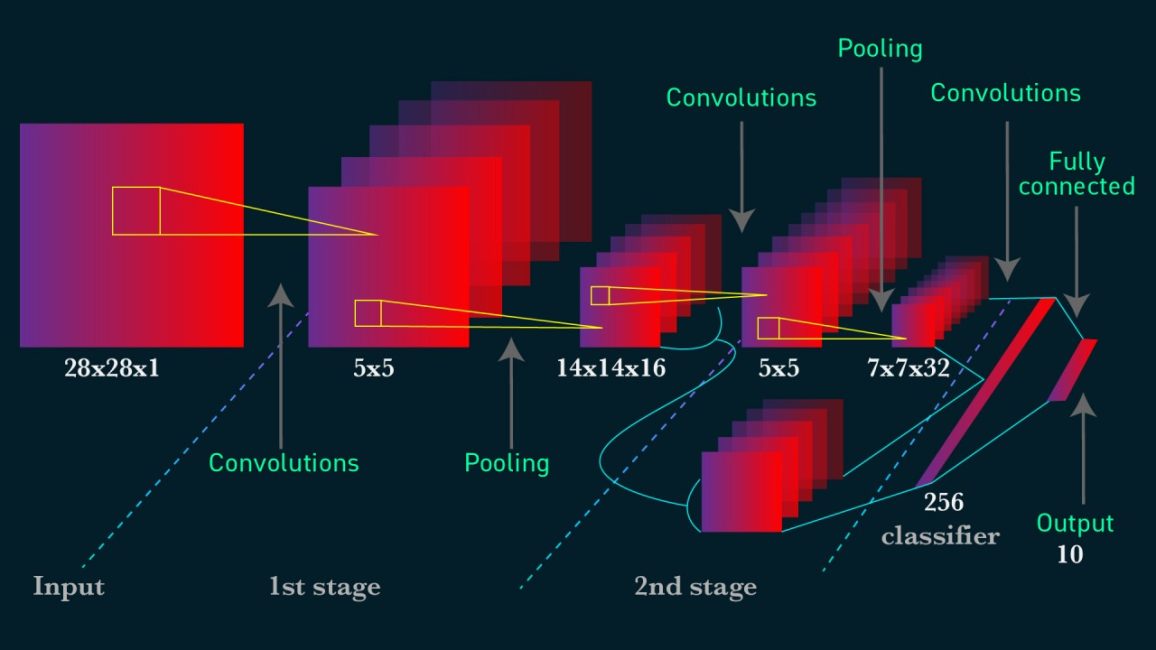
ساختار کلی یک شبکه CNN
یک شبکه عصبی کانولوشنی معمولاً از چند بخش اصلی تشکیل میشود:
- لایه ورودی (Input Layer)
- لایه کانولوشن (Convolution Layer)
- لایه فعالسازی (Activation Layer)
- لایه Pooling
- لایه Fully Connected
- لایه خروجی (Output Layer)
هر یک از این بخشها وظیفه خاصی دارند.
لایه ورودی (Input Layer)
در ابتدا تصویر وارد شبکه میشود.
برای مثال، یک تصویر رنگی با ابعاد ۲۲۴×۲۲۴ دارای سه کانال رنگی است:
- قرمز (Red)
- سبز (Green)
- آبی (Blue)
بنابراین، شبکه کار خود را با دریافت اطلاعات خام تصویر آغاز میکند.
لایه کانولوشن (Convolution Layer)
مهمترین بخش CNN لایه کانولوشن است.
در این مرحله، فیلترهای کوچکی روی تصویر حرکت میکنند و به دنبال الگوهای خاص میگردند.
برای مثال، یک فیلتر ممکن است:
- لبههای عمودی را تشخیص دهد.
- لبههای افقی را شناسایی کند.
- گوشهها را پیدا کند.
- بافتها را استخراج کند.
در نتیجه، ویژگیهای مهم تصویر استخراج میشوند.
مفهوم فیلتر (Kernel)
فیلتر یا Kernel یک ماتریس کوچک است که روی تصویر حرکت میکند.
برای نمونه، یک فیلتر ۳×۳ ممکن است به شکل زیر باشد:
| ۱ | ۰ | -۱ |
|---|---|---|
| ۱ | ۰ | -۱ |
| ۱ | ۰ | -۱ |
این فیلتر معمولاً برای تشخیص لبههای عمودی در تصویر استفاده میشود.
به همین دلیل، فیلترها نقش بسیار مهمی در استخراج ویژگیها دارند.
لایه فعالسازی (Activation Layer)
پس از عملیات کانولوشن، معمولاً از تابع فعالسازی استفاده میشود.
رایجترین تابع فعالسازی در CNN تابع ReLU است.
فرمول تابع ReLU به صورت زیر است:
ReLU(x) = max(0, x)
به زبان ساده:
- اگر مقدار x مثبت باشد، خروجی همان x خواهد بود.
- اگر مقدار x منفی باشد، خروجی صفر میشود.
مثال:
- ReLU(5) = 5
- ReLU(2) = 2
- ReLU(-3) = 0
- ReLU(-10) = 0
این تابع تمام مقادیر منفی را صفر میکند.
در نتیجه:
- آموزش سریعتر میشود.
- شبکه بهتر یاد میگیرد.
- مشکل ناپدید شدن گرادیان کاهش پیدا میکند.
لایه Pooling چیست؟
پس از استخراج ویژگیها، حجم دادهها هنوز زیاد است.
برای کاهش حجم اطلاعات از Pooling استفاده میشود.
رایجترین نوع آن Max Pooling است.
در این روش، بزرگترین مقدار هر ناحیه انتخاب میشود.
برای مثال اگر یک ناحیه ۲×۲ به شکل زیر داشته باشیم:
| ۱ | ۵ |
|---|---|
| ۳ | ۲ |
خروجی Max Pooling برابر با عدد ۵ خواهد بود؛ زیرا بزرگترین مقدار این ناحیه است.
مزایای Pooling عبارتاند از:
- کاهش تعداد پارامترها
- افزایش سرعت پردازش
- کاهش مصرف حافظه
- جلوگیری از بیشبرازش
CNN چگونه ویژگیها را یاد میگیرد؟
در لایههای ابتدایی، شبکه ویژگیهای بسیار ساده را تشخیص میدهد.
برای مثال:
- خطوط
- لبهها
- گوشهها
اما در لایههای عمیقتر، ویژگیهای پیچیدهتر شناسایی میشوند.
برای مثال:
- چشم
- بینی
- چرخ خودرو
- بال پرنده
در نهایت، شبکه میتواند کل شیء را تشخیص دهد.
این ویژگی یکی از دلایل موفقیت CNN در بینایی کامپیوتر است.
لایه Fully Connected
پس از استخراج ویژگیها، اطلاعات وارد لایه Fully Connected میشوند.
این بخش شبیه شبکههای عصبی سنتی عمل میکند.
در این مرحله، شبکه تصمیم میگیرد تصویر متعلق به کدام دسته است.
برای مثال:
- گربه
- سگ
- خودرو
- هواپیما
در نتیجه، طبقهبندی نهایی انجام میشود.
فرآیند آموزش CNN
برای آموزش شبکه، تعداد زیادی تصویر برچسبگذاریشده استفاده میشود.
برای مثال:
- هزاران تصویر گربه
- هزاران تصویر سگ
شبکه ابتدا پیشبینی انجام میدهد.
سپس میزان خطا محاسبه میشود.
بعد از آن، الگوریتم Backpropagation وزنهای شبکه را اصلاح میکند.
این فرآیند هزاران بار تکرار میشود تا مدل به دقت بالایی برسد.
مزایای شبکههای عصبی کانولوشنی
CNN مزایای متعددی دارد که باعث محبوبیت آن شده است.
استخراج خودکار ویژگیها
نیازی به طراحی دستی ویژگیها وجود ندارد.
دقت بالا
در بسیاری از مسائل بینایی کامپیوتر عملکرد فوقالعادهای دارد.
مقیاسپذیری مناسب
برای تصاویر کوچک و بزرگ قابل استفاده است.
یادگیری الگوهای پیچیده
مدل میتواند ساختارهای بسیار پیچیده را شناسایی کند.
کاربردهای CNN
شبکههای عصبی کانولوشنی در بسیاری از فناوریهای مدرن استفاده میشوند.
تشخیص چهره
سیستمهای امنیتی و گوشیهای هوشمند از CNN استفاده میکنند.
تشخیص اشیا
مدلهایی مانند YOLO و Faster R-CNN بر پایه CNN توسعه یافتهاند.
خودروهای خودران
تشخیص جاده، خودروها و عابران پیاده با کمک CNN انجام میشود.
پزشکی
تحلیل تصاویر MRI و CT Scan یکی از مهمترین کاربردهای این فناوری است.
تشخیص پلاک خودرو
سیستمهای ANPR از CNN برای شناسایی پلاکها استفاده میکنند.
محدودیتهای CNN
با وجود مزایای فراوان، CNN بدون نقص نیست.
نیاز به داده زیاد
برای دستیابی به دقت بالا معمولاً به حجم بزرگی از داده نیاز است.
هزینه پردازشی بالا
آموزش مدلهای بزرگ به سختافزار قدرتمند نیاز دارد.
دشواری تفسیر
در بسیاری از موارد مشخص نیست شبکه دقیقاً چگونه تصمیم گرفته است.
CNN یا Vision Transformer؟
در سالهای اخیر Vision Transformer به رقیب جدی CNN تبدیل شده است.
با این حال، CNN همچنان در بسیاری از پروژهها استفاده میشود.
در واقع:
- CNN برای پروژههای کوچک و متوسط بسیار مناسب است.
- Vision Transformer در مجموعه دادههای بزرگ عملکرد بهتری دارد.
به همین دلیل، هر دو فناوری همچنان نقش مهمی در بینایی کامپیوتر دارند.
آینده شبکههای عصبی کانولوشنی
اگرچه مدلهای جدیدی معرفی شدهاند، اما CNN هنوز یکی از مهمترین فناوریهای هوش مصنوعی محسوب میشود.
علاوه بر این، بسیاری از معماریهای مدرن از ترکیب CNN و Transformer استفاده میکنند.
در نتیجه، انتظار میرود شبکههای کانولوشنی در سالهای آینده نیز نقش مهمی در توسعه سیستمهای هوشمند داشته باشند.
جمعبندی
شبکههای عصبی کانولوشنی (CNN) یکی از مهمترین دستاوردهای یادگیری عمیق در حوزه بینایی کامپیوتر هستند. این شبکهها با استفاده از لایههای کانولوشن، فعالسازی و Pooling میتوانند ویژگیهای مهم تصاویر را استخراج کرده و اشیا را با دقت بالا شناسایی کنند. امروزه از CNN در تشخیص چهره، خودروهای خودران، پزشکی، تشخیص پلاک خودرو و بسیاری از فناوریهای پیشرفته دیگر استفاده میشود. با وجود ظهور مدلهای جدید، CNN همچنان یکی از پایههای اصلی بینایی کامپیوتر به شمار میرود.